At work, we have an old codebase, originally written on Unix. While porting it to Windows someone's decided that Microsoft standard library is not good enough and replaced most of the functions with his own minimal implementations, mostly by copying relevant pieces from older projects he was working on. So we have a bare minimum of CRT, written in 90ths style. Which is good, in some way. It survived two decades and works fine, but recently we started thinking that maybe we should update some hot functions to improve performance. So, I've decided to research what benefit we can get from modern programming technics starting with the simplest one, with strlen.
Actually, strlen is usually an intrinsic, which means we can't find its implementation in the library's source code: compiler produces it instead. Which doesn't always mean its optimal. Anyway, we can still see what it performance look like and we can replace it if we need.
The traditional "strlen" K&R-style implementation used to be something like that:
Or, maybe this. It can be optimized into "repnz scanb" instruction. Which made a difference on older processors.
With modern processors, there are two choices. We can use special SSE instructions, coding them on assembler or using compiler extensions. If we want to stay in C/C++ world, we can process 8 bytes at once by using 64-bit arithmetic and logical instructions. We can fetch 8 bytes as 64-bit word, then somehow determine if the word contains a zero byte. If it does not, we can increment length by 8 and jump to the next 8 bytes. If it does, we need to find the zero byte inside that word. The processing of the last word is not that performance-critical, its happens just once per string.
I know there are implementations (like GCC GNU library), but I like to reinvent a bicycle, so I wrote it myself for a bit of fun, relying on compiler to optimize trivialities:
Explanation:
Finding a non-zero bit in 64-bit word can also be a little of a fun play, and I'll show some examples below. Also, the Intel SSE2 has instructions to do all that by one single command. SSE4 is also can be used, but I saw posts, explaining that SSE2 implementation is faster, so I've decided to skip SSE4 for now.
Let's go to tests. I wrote 9 variants of strlen (sources at the end of this post):
Each of methods computes length of strings from 0 to 64. That is repeated 100000 times and time is reported in milliseconds. Every test is repeated 8 times using 8 different alignments of original strings.
Note, that higher bar means worse performance. Groups are for different variants, and inside each group we can see results for different alignments.
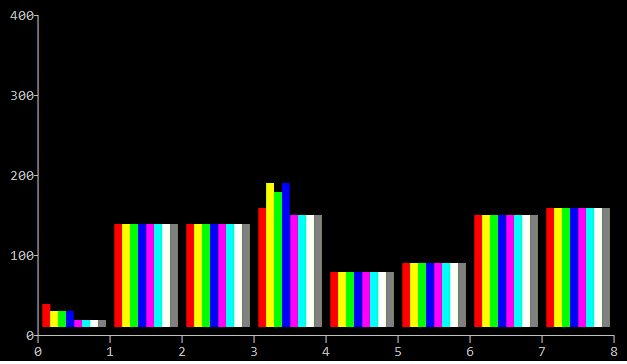
First run was on my home mac-mini machine (2.3 GHz Intel Core i7, Maverick):
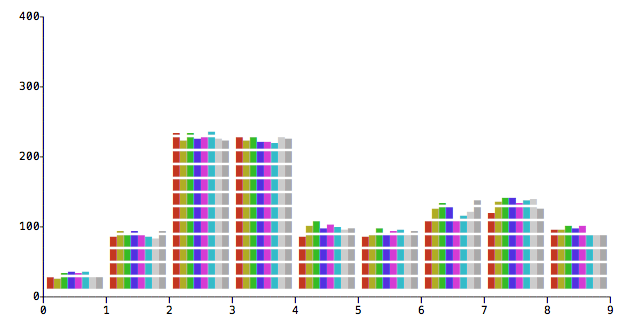
We can see, that per-byte methods 2,3 are the worst, methods 1, 4, 5, 8 has almost identical performance. Which is a surprise, I thought that SSE2 will be better, it runs 128bit at once, not 64. Also, alignment of strings doesn't seems to matter, which is another surprise.
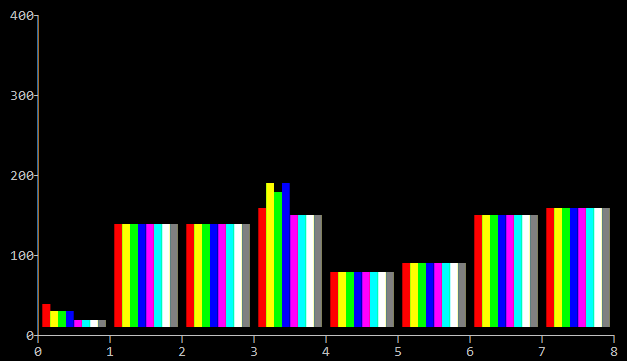
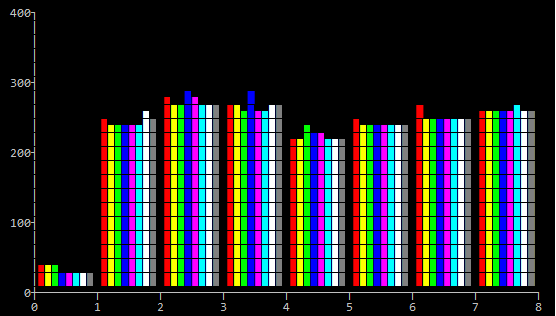
And the second is on my travel macbook (Processor 1.1 GHz Intel Core M, Sierra):

Below is a result of running test on Windows, with our project compiler and library, by two machines: a newer one (Intel Xeon CPU E5-1650 v3 @ 3.50GHz; Windows Server 2016, 64 bit) and an older one (Intel Core i7 CPU 920 @ 2.67Ghz; Windows Server 2008R2, 64 bit). Also I didn't run SSE2 test on them.

So, the built-in and per-byte tests are the worst. The older machine, the less that difference.
Also, I run the test with 32-bit compiler and the results are similar.
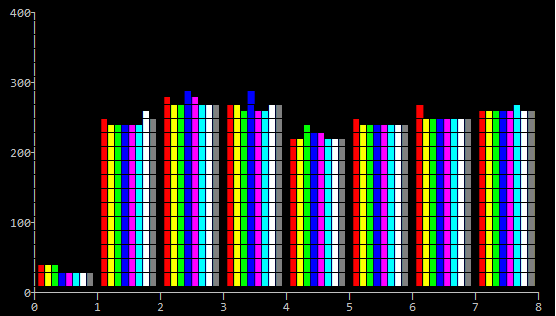
So, the morale is that per-byte is bad and 64-bit C++ is as good as SSE2.
Here is the code:
Actually, strlen is usually an intrinsic, which means we can't find its implementation in the library's source code: compiler produces it instead. Which doesn't always mean its optimal. Anyway, we can still see what it performance look like and we can replace it if we need.
The traditional "strlen" K&R-style implementation used to be something like that:
int strlen(const char *s){
uint l=0; while(*s++) l++; return l;
}
Or, maybe this. It can be optimized into "repnz scanb" instruction. Which made a difference on older processors.
int strlen(const char *s){
const char *s0=s; while(*s) s++; return s-s0;
}
With modern processors, there are two choices. We can use special SSE instructions, coding them on assembler or using compiler extensions. If we want to stay in C/C++ world, we can process 8 bytes at once by using 64-bit arithmetic and logical instructions. We can fetch 8 bytes as 64-bit word, then somehow determine if the word contains a zero byte. If it does not, we can increment length by 8 and jump to the next 8 bytes. If it does, we need to find the zero byte inside that word. The processing of the last word is not that performance-critical, its happens just once per string.
I know there are implementations (like GCC GNU library), but I like to reinvent a bicycle, so I wrote it myself for a bit of fun, relying on compiler to optimize trivialities:
int strlen4(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
s=(const char *)p; while(*s) s++; return c+(s-(const char *)p);
}
c+=8; p++;
}
}
Explanation:
- ~m is 0x07f7f7f7f7f7f7f7full by the way, and 'full' is a coincidence
- *p&~m // zeroing 8th bit of every byte
- (*p&~m)+~m // arithmetic addition will overflow to 8th bit when an only when the value on step 1 is non-zero, and it never overflow to the next byte
- ((*p&~m)+~m)|*p) // or-ing with original word will set 8th bit to one when 8th bit of *p is non-zero, and it also never overflow
- ((*p&~m)+~m)|*p)&m // selecting only 8th bits of every byte, which would be 1 when byte of *p is non-zero and 0 when it zero
- ((*p&~m)+~m)|*p)&m^m // inverting that bits, so it will have 1 for zero byte and 0 for non-zero
- now if entire word is 0, that means we don't have zero bytes
Finding a non-zero bit in 64-bit word can also be a little of a fun play, and I'll show some examples below. Also, the Intel SSE2 has instructions to do all that by one single command. SSE4 is also can be used, but I saw posts, explaining that SSE2 implementation is faster, so I've decided to skip SSE4 for now.
Let's go to tests. I wrote 9 variants of strlen (sources at the end of this post):
- 0: no strlen is called, but all other test code is running -- to determine the baseline.
- 1: calling just regular built-in "strlen"
- 2-3: simple byte-per-byte implementations
- 4-7: algorithm described above with different code determining the length of the last word, where methods 6-7 don't use conditional ifs
- 8: using SSE2 intrinsics
Each of methods computes length of strings from 0 to 64. That is repeated 100000 times and time is reported in milliseconds. Every test is repeated 8 times using 8 different alignments of original strings.
Note, that higher bar means worse performance. Groups are for different variants, and inside each group we can see results for different alignments.
First run was on my home mac-mini machine (2.3 GHz Intel Core i7, Maverick):
We can see, that per-byte methods 2,3 are the worst, methods 1, 4, 5, 8 has almost identical performance. Which is a surprise, I thought that SSE2 will be better, it runs 128bit at once, not 64. Also, alignment of strings doesn't seems to matter, which is another surprise.
And the second is on my travel macbook (Processor 1.1 GHz Intel Core M, Sierra):
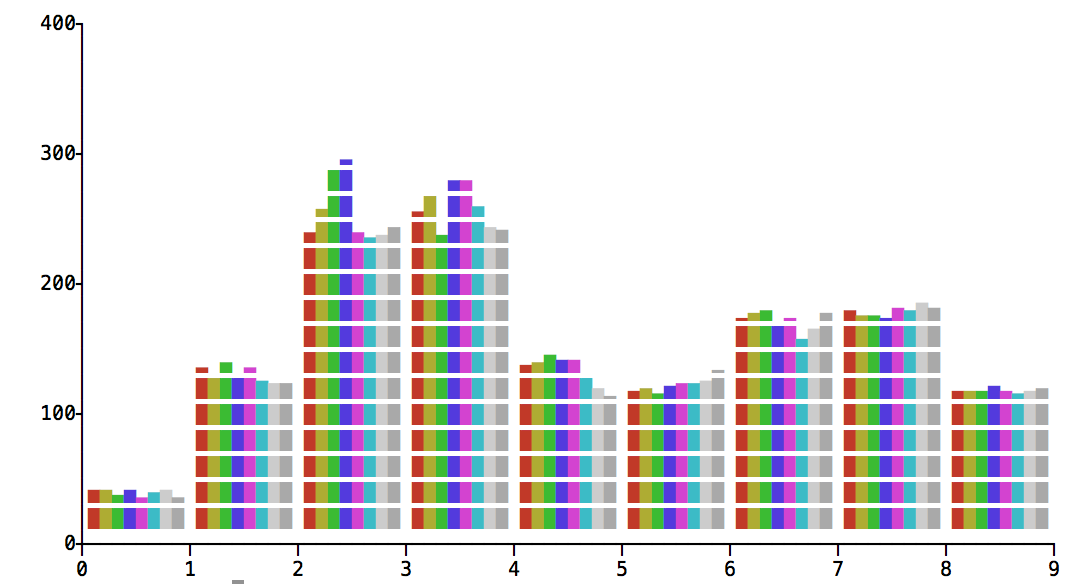
Below is a result of running test on Windows, with our project compiler and library, by two machines: a newer one (Intel Xeon CPU E5-1650 v3 @ 3.50GHz; Windows Server 2016, 64 bit) and an older one (Intel Core i7 CPU 920 @ 2.67Ghz; Windows Server 2008R2, 64 bit). Also I didn't run SSE2 test on them.
So, the built-in and per-byte tests are the worst. The older machine, the less that difference.
Also, I run the test with 32-bit compiler and the results are similar.
So, the morale is that per-byte is bad and 64-bit C++ is as good as SSE2.
Here is the code:
int _strlen1(const char *s){
return strlen(s);
}
int _strlen2(const char *s){
const char *s0=s; while(*s) s++; return s-s0;
}
int _strlen3(const char *s){
uint l=0; while(*s){ s++; l++; } return l;
}
int _strlen4(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
s=(const char *)p; while(*s) s++; return c+(s-(const char *)p);
}
c+=8; p++;
}
}
int _strlen5(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x) return x&0x00000000ffffffffull ?
(x&0x000000000000ffffull ?
(x&0x00000000000000ffull ? c : c+1) :
(x&0x0000000000ff0000ull ? c+2 : c+3)) :
(x&0x0000ffff00000000ull ?
(x&0x000000ff00000000ull ? c+4 : c+5) :
(x&0x00ff000000000000ull ? c+6 : c+7));
c+=8; p++;
}
}
int _strlen6(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
const uint64 y=(x|(x<<8)|(x<<16)|(x<<24)|(x<<32)|(x<<40)|(x<<48)|(x<<56))^m;
const uint64 z=y+(y>>8), u=z+(z>>16), l=u+(u>>32);
return c+((l>>7)&0xf);
}
c+=8; p++;
}
}
int _strlen7(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
const uint64 y=(x|(x<<8)|(x<<16)|(x<<24)|(x<<32)|(x<<40)|(x<<48)|(x<<56))^m;
const uint64 l=y+(y>>8)+(y>>16)+(y>>24)+(y>>32)+(y>>40)+(y>>48)+(y>>56);
return c+((l>>7)&0xf);
}
c+=8; p++;
}
}
int _strlen8(const char *s){
const __m128i z = _mm_setzero_si128();
const __m128i* p = (const __m128i*)s;
for(;;){
__m128i xmm = _mm_loadu_si128(p);
const uint mask = _mm_movemask_epi8(_mm_cmpeq_epi8(xmm,z));
if(mask!=0) return ((const char*)p)-s+(ffs(mask)-1);
p++;
}
}
4 comments:
What was the mean length of strings? Due to sentence "The processing of the last word is not that performance-critical" a think that you processed huge strings. But as usual, strlen is used with short strings (tens of bytes).
In my test, it was a set of 64 strings with lengths 0,1,2,3...63, so average length is 31.5. Which is about 8*4, so tail is only 1/4. As tests show, the tail computation time does matter, variants 6-7 are noticeably slower than 4-5, being different in only tail computation.
You are right, there are cases, when all strings are shorter than 8. If I consider my own C++, almost all variable names are shorter, so if I'm writing a compiler, all strings will fit one word, which BTW would be the most optimal way of working with them.
The effective method reads memory out of string. Is it possible to get exception? For example, what if the empty string begins at the last byte of memory for process?
That test never goes out of processor cache, so there is no random memory acces. In real life times will be somehow different, maybe I should write another test for them.
I thought about exceptions. We can only have exception when crossing page boundary, so it can't happen when string is 64-bit aligned. For practical use, we can count first non-aligned bytes one-by-one or maybe fetch previous aligned word and do some smart logic.
Post a Comment