 Давно я ничего здесь не писал. Надо снова с чего-то начать, проще всего с фотографии, а еще проще - с чужой. Эту фотку Игорь прислал из Непала.
Давно я ничего здесь не писал. Надо снова с чего-то начать, проще всего с фотографии, а еще проще - с чужой. Эту фотку Игорь прислал из Непала.2017-12-29
Everest Base Camp
Давно я ничего здесь не писал. Надо снова с чего-то начать, проще всего с фотографии, а еще проще - с чужой. Эту фотку Игорь прислал из Непала.2017-09-09
2017-08-25
Total Solar Eclipse
Полное солнечное затмение неподалеку происходит настолько редко, что попадает под категорию "раз в жизни". Поэтому мы, когда узнали, что путь затмения проходит по соседнему штату, сразу решили поехать посмотреть.
Конечно, комнату в городке в "zone of totality" снять не удалось даже за полгода до события. Пара комнат, что были доступны уже стоили порядка тысячи долларов за ночь. Мы сняли местечко под палатку на реке Колумбия в часе езды от зоны затмнения. Парк на берегу Dechutes River был приятен сам-по-себе.
 В новостях сообщали о миллионе человек, которые приедут в зону. Затмнение должно было произойти около десяти утра, мы проснулись пол-пятого, наскоро в темноте выпили приготовленный с вечера кофе и поехали, надеясь успеть проехать до начала пробки. Мы поехали в город Антилопа, который находится в северной части полосы полного затмнения. Немного недоехав до города мы обнаружили удобную площадку на возвышенности, на которой уже стояло много машин и палаток. Похоже, многие стояли там с вечера. Мы подумали, что "the more the merrier" и встали там же. Народ стоял капитально, со штативами, телескопами и полными походными холодильниками.
В новостях сообщали о миллионе человек, которые приедут в зону. Затмнение должно было произойти около десяти утра, мы проснулись пол-пятого, наскоро в темноте выпили приготовленный с вечера кофе и поехали, надеясь успеть проехать до начала пробки. Мы поехали в город Антилопа, который находится в северной части полосы полного затмнения. Немного недоехав до города мы обнаружили удобную площадку на возвышенности, на которой уже стояло много машин и палаток. Похоже, многие стояли там с вечера. Мы подумали, что "the more the merrier" и встали там же. Народ стоял капитально, со штативами, телескопами и полными походными холодильниками.
 Начало затмнения увидеть без специальных очков невозможно. Мы запаслись правильными очками заранее. Эти очки в картонных оправах продавали большими пачками, так что лишние раздавали на месте соседям и всем желающим. В очках видно, как луна начала заползать на диск солнца почти за час до наступления полного затмнения, но без очков никакой разницы не было видно. Так что мы сидели и ждали. Когда от солнца остался лишь узкий серп, визуально все еще ничего не было заметно, но мы почувствовали, что стало заметно холоднее. Солнце светило, но больше не пекло. Затем стало как-то странно темнеть. Казалось бы день, солнце высоко, блики, тени, но какие-то не яркие, приглушенные.
Начало затмнения увидеть без специальных очков невозможно. Мы запаслись правильными очками заранее. Эти очки в картонных оправах продавали большими пачками, так что лишние раздавали на месте соседям и всем желающим. В очках видно, как луна начала заползать на диск солнца почти за час до наступления полного затмнения, но без очков никакой разницы не было видно. Так что мы сидели и ждали. Когда от солнца остался лишь узкий серп, визуально все еще ничего не было заметно, но мы почувствовали, что стало заметно холоднее. Солнце светило, но больше не пекло. Затем стало как-то странно темнеть. Казалось бы день, солнце высоко, блики, тени, но какие-то не яркие, приглушенные.
 И затем вдруг резко, за секунды, стало темнеть со всех сторон сразу. Небо стало темно-синим, появились закатные цвета на горизонте со всех сторон. И вдруг солнце стало черным. Только-что оно было ярким и вдруг на его месте появился черный круг с серебристым кольцом вокруг. Впечатляюще. Народ вокруг завизжал от восторга. Это длилось около минуты. Я попытался сфоткать, но как-то неудачно, неподготовленно. Да я и не надеялся обойти тех, кто с телескопами.
И затем вдруг резко, за секунды, стало темнеть со всех сторон сразу. Небо стало темно-синим, появились закатные цвета на горизонте со всех сторон. И вдруг солнце стало черным. Только-что оно было ярким и вдруг на его месте появился черный круг с серебристым кольцом вокруг. Впечатляюще. Народ вокруг завизжал от восторга. Это длилось около минуты. Я попытался сфоткать, но как-то неудачно, неподготовленно. Да я и не надеялся обойти тех, кто с телескопами.
 А потом вдруг появился первый лучик солнца из за луны, и все мгновенно просветлело, черный диск исчез и день продолжился как раньше. Народ взвизггнул еще раз и постепенно начал разъезжаться, чтобы успеть уехать до пробок. Мы выпили второй заготовленный кофе и поехали тоже.
А потом вдруг появился первый лучик солнца из за луны, и все мгновенно просветлело, черный диск исчез и день продолжился как раньше. Народ взвизггнул еще раз и постепенно начал разъезжаться, чтобы успеть уехать до пробок. Мы выпили второй заготовленный кофе и поехали тоже.
Вообще, зрелище впечатляет. Не так, как в древние времена, когда это был знак божий, показывающий владыке либо разрешение грабить соседнее государство, либо наоборот, приказ оставить его в покое, но все равно впечатляет, несмотря на полное понимание нами планетарной механистичности явления. Необъяснимое совпадение угловых размеров луны и солнца впечатляет тоже.
Конечно, комнату в городке в "zone of totality" снять не удалось даже за полгода до события. Пара комнат, что были доступны уже стоили порядка тысячи долларов за ночь. Мы сняли местечко под палатку на реке Колумбия в часе езды от зоны затмнения. Парк на берегу Dechutes River был приятен сам-по-себе.
 В новостях сообщали о миллионе человек, которые приедут в зону. Затмнение должно было произойти около десяти утра, мы проснулись пол-пятого, наскоро в темноте выпили приготовленный с вечера кофе и поехали, надеясь успеть проехать до начала пробки. Мы поехали в город Антилопа, который находится в северной части полосы полного затмнения. Немного недоехав до города мы обнаружили удобную площадку на возвышенности, на которой уже стояло много машин и палаток. Похоже, многие стояли там с вечера. Мы подумали, что "the more the merrier" и встали там же. Народ стоял капитально, со штативами, телескопами и полными походными холодильниками.
В новостях сообщали о миллионе человек, которые приедут в зону. Затмнение должно было произойти около десяти утра, мы проснулись пол-пятого, наскоро в темноте выпили приготовленный с вечера кофе и поехали, надеясь успеть проехать до начала пробки. Мы поехали в город Антилопа, который находится в северной части полосы полного затмнения. Немного недоехав до города мы обнаружили удобную площадку на возвышенности, на которой уже стояло много машин и палаток. Похоже, многие стояли там с вечера. Мы подумали, что "the more the merrier" и встали там же. Народ стоял капитально, со штативами, телескопами и полными походными холодильниками. Начало затмнения увидеть без специальных очков невозможно. Мы запаслись правильными очками заранее. Эти очки в картонных оправах продавали большими пачками, так что лишние раздавали на месте соседям и всем желающим. В очках видно, как луна начала заползать на диск солнца почти за час до наступления полного затмнения, но без очков никакой разницы не было видно. Так что мы сидели и ждали. Когда от солнца остался лишь узкий серп, визуально все еще ничего не было заметно, но мы почувствовали, что стало заметно холоднее. Солнце светило, но больше не пекло. Затем стало как-то странно темнеть. Казалось бы день, солнце высоко, блики, тени, но какие-то не яркие, приглушенные.
Начало затмнения увидеть без специальных очков невозможно. Мы запаслись правильными очками заранее. Эти очки в картонных оправах продавали большими пачками, так что лишние раздавали на месте соседям и всем желающим. В очках видно, как луна начала заползать на диск солнца почти за час до наступления полного затмнения, но без очков никакой разницы не было видно. Так что мы сидели и ждали. Когда от солнца остался лишь узкий серп, визуально все еще ничего не было заметно, но мы почувствовали, что стало заметно холоднее. Солнце светило, но больше не пекло. Затем стало как-то странно темнеть. Казалось бы день, солнце высоко, блики, тени, но какие-то не яркие, приглушенные. И затем вдруг резко, за секунды, стало темнеть со всех сторон сразу. Небо стало темно-синим, появились закатные цвета на горизонте со всех сторон. И вдруг солнце стало черным. Только-что оно было ярким и вдруг на его месте появился черный круг с серебристым кольцом вокруг. Впечатляюще. Народ вокруг завизжал от восторга. Это длилось около минуты. Я попытался сфоткать, но как-то неудачно, неподготовленно. Да я и не надеялся обойти тех, кто с телескопами.
И затем вдруг резко, за секунды, стало темнеть со всех сторон сразу. Небо стало темно-синим, появились закатные цвета на горизонте со всех сторон. И вдруг солнце стало черным. Только-что оно было ярким и вдруг на его месте появился черный круг с серебристым кольцом вокруг. Впечатляюще. Народ вокруг завизжал от восторга. Это длилось около минуты. Я попытался сфоткать, но как-то неудачно, неподготовленно. Да я и не надеялся обойти тех, кто с телескопами. А потом вдруг появился первый лучик солнца из за луны, и все мгновенно просветлело, черный диск исчез и день продолжился как раньше. Народ взвизггнул еще раз и постепенно начал разъезжаться, чтобы успеть уехать до пробок. Мы выпили второй заготовленный кофе и поехали тоже.
А потом вдруг появился первый лучик солнца из за луны, и все мгновенно просветлело, черный диск исчез и день продолжился как раньше. Народ взвизггнул еще раз и постепенно начал разъезжаться, чтобы успеть уехать до пробок. Мы выпили второй заготовленный кофе и поехали тоже.Вообще, зрелище впечатляет. Не так, как в древние времена, когда это был знак божий, показывающий владыке либо разрешение грабить соседнее государство, либо наоборот, приказ оставить его в покое, но все равно впечатляет, несмотря на полное понимание нами планетарной механистичности явления. Необъяснимое совпадение угловых размеров луны и солнца впечатляет тоже.
2017-08-08
Mt. Rainier

В субботу мы поехали на Rainier и прошли по Skyline Trail. Гора в тумане, который на самом деле не туман, а дым от горящих в Британской Колумбии лесов. Стоит очень сухая погода: дождя не было уже почти два месяца, что нетипично для нашего климата.
Mount St. Helens

В середине июля Игорь снова решил участвовать в популярном велопробеге Seattle to Portland (сокращенно "STP", 325km). А мы поехали его встречать на машине, с ночевкой и посещением горы St. Helens. Эта гора - действующий вулкан, который извергался в 1980г, что стало местной катастрофой и самым сильным вулканическим извержением в штатах. На youtube есть фильмы про катастрофу. Фотка сделана с Johnston Ridge, который назван в честь вулканолога David Johnston, которой погиб наблюдая за извержением.

А Игорь приехал, да, за один день. Ира сфотографировала его своим телефоном, который сделал удивительно удачное фото. Это не обработка, это просто фото с телефона.


2017-07-29
Peggy's Cove

Peggy's Cove - небольшой рыбацко-туристский городок в "Новой Шотландии". Мы немного попутешествовали по этой Канадской провинции в июле. И ниже панорама того же места.





2017-05-29
strlen
At work, we have an old codebase, originally written on Unix. While porting it to Windows someone's decided that Microsoft standard library is not good enough and replaced most of the functions with his own minimal implementations, mostly by copying relevant pieces from older projects he was working on. So we have a bare minimum of CRT, written in 90ths style. Which is good, in some way. It survived two decades and works fine, but recently we started thinking that maybe we should update some hot functions to improve performance. So, I've decided to research what benefit we can get from modern programming technics starting with the simplest one, with strlen.
Actually, strlen is usually an intrinsic, which means we can't find its implementation in the library's source code: compiler produces it instead. Which doesn't always mean its optimal. Anyway, we can still see what it performance look like and we can replace it if we need.
The traditional "strlen" K&R-style implementation used to be something like that:
Or, maybe this. It can be optimized into "repnz scanb" instruction. Which made a difference on older processors.
With modern processors, there are two choices. We can use special SSE instructions, coding them on assembler or using compiler extensions. If we want to stay in C/C++ world, we can process 8 bytes at once by using 64-bit arithmetic and logical instructions. We can fetch 8 bytes as 64-bit word, then somehow determine if the word contains a zero byte. If it does not, we can increment length by 8 and jump to the next 8 bytes. If it does, we need to find the zero byte inside that word. The processing of the last word is not that performance-critical, its happens just once per string.
I know there are implementations (like GCC GNU library), but I like to reinvent a bicycle, so I wrote it myself for a bit of fun, relying on compiler to optimize trivialities:
Explanation:
Finding a non-zero bit in 64-bit word can also be a little of a fun play, and I'll show some examples below. Also, the Intel SSE2 has instructions to do all that by one single command. SSE4 is also can be used, but I saw posts, explaining that SSE2 implementation is faster, so I've decided to skip SSE4 for now.
Let's go to tests. I wrote 9 variants of strlen (sources at the end of this post):
Each of methods computes length of strings from 0 to 64. That is repeated 100000 times and time is reported in milliseconds. Every test is repeated 8 times using 8 different alignments of original strings.
Note, that higher bar means worse performance. Groups are for different variants, and inside each group we can see results for different alignments.
First run was on my home mac-mini machine (2.3 GHz Intel Core i7, Maverick):
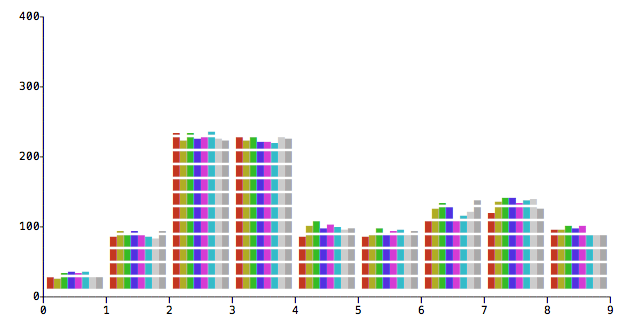
We can see, that per-byte methods 2,3 are the worst, methods 1, 4, 5, 8 has almost identical performance. Which is a surprise, I thought that SSE2 will be better, it runs 128bit at once, not 64. Also, alignment of strings doesn't seems to matter, which is another surprise.
And the second is on my travel macbook (Processor 1.1 GHz Intel Core M, Sierra):

Below is a result of running test on Windows, with our project compiler and library, by two machines: a newer one (Intel Xeon CPU E5-1650 v3 @ 3.50GHz; Windows Server 2016, 64 bit) and an older one (Intel Core i7 CPU 920 @ 2.67Ghz; Windows Server 2008R2, 64 bit). Also I didn't run SSE2 test on them.

So, the built-in and per-byte tests are the worst. The older machine, the less that difference.
Also, I run the test with 32-bit compiler and the results are similar.
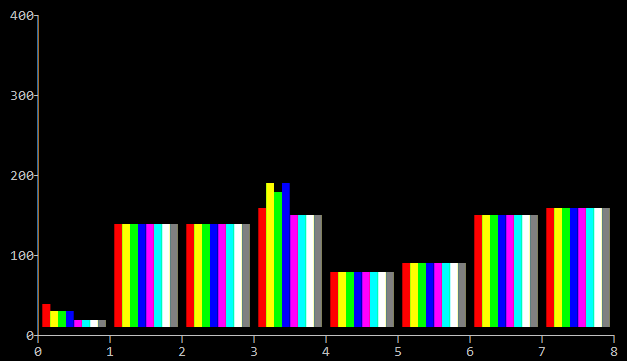
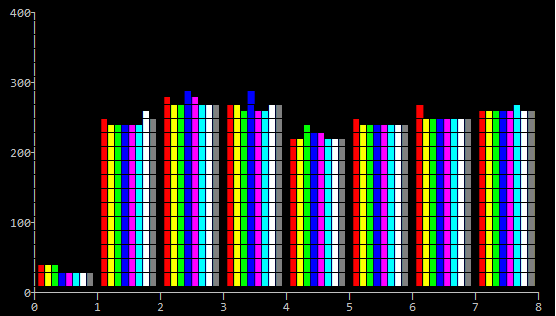
So, the morale is that per-byte is bad and 64-bit C++ is as good as SSE2.
Here is the code:
Actually, strlen is usually an intrinsic, which means we can't find its implementation in the library's source code: compiler produces it instead. Which doesn't always mean its optimal. Anyway, we can still see what it performance look like and we can replace it if we need.
The traditional "strlen" K&R-style implementation used to be something like that:
int strlen(const char *s){
uint l=0; while(*s++) l++; return l;
}
Or, maybe this. It can be optimized into "repnz scanb" instruction. Which made a difference on older processors.
int strlen(const char *s){
const char *s0=s; while(*s) s++; return s-s0;
}
With modern processors, there are two choices. We can use special SSE instructions, coding them on assembler or using compiler extensions. If we want to stay in C/C++ world, we can process 8 bytes at once by using 64-bit arithmetic and logical instructions. We can fetch 8 bytes as 64-bit word, then somehow determine if the word contains a zero byte. If it does not, we can increment length by 8 and jump to the next 8 bytes. If it does, we need to find the zero byte inside that word. The processing of the last word is not that performance-critical, its happens just once per string.
I know there are implementations (like GCC GNU library), but I like to reinvent a bicycle, so I wrote it myself for a bit of fun, relying on compiler to optimize trivialities:
int strlen4(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
s=(const char *)p; while(*s) s++; return c+(s-(const char *)p);
}
c+=8; p++;
}
}
Explanation:
- ~m is 0x07f7f7f7f7f7f7f7full by the way, and 'full' is a coincidence
- *p&~m // zeroing 8th bit of every byte
- (*p&~m)+~m // arithmetic addition will overflow to 8th bit when an only when the value on step 1 is non-zero, and it never overflow to the next byte
- ((*p&~m)+~m)|*p) // or-ing with original word will set 8th bit to one when 8th bit of *p is non-zero, and it also never overflow
- ((*p&~m)+~m)|*p)&m // selecting only 8th bits of every byte, which would be 1 when byte of *p is non-zero and 0 when it zero
- ((*p&~m)+~m)|*p)&m^m // inverting that bits, so it will have 1 for zero byte and 0 for non-zero
- now if entire word is 0, that means we don't have zero bytes
Finding a non-zero bit in 64-bit word can also be a little of a fun play, and I'll show some examples below. Also, the Intel SSE2 has instructions to do all that by one single command. SSE4 is also can be used, but I saw posts, explaining that SSE2 implementation is faster, so I've decided to skip SSE4 for now.
Let's go to tests. I wrote 9 variants of strlen (sources at the end of this post):
- 0: no strlen is called, but all other test code is running -- to determine the baseline.
- 1: calling just regular built-in "strlen"
- 2-3: simple byte-per-byte implementations
- 4-7: algorithm described above with different code determining the length of the last word, where methods 6-7 don't use conditional ifs
- 8: using SSE2 intrinsics
Each of methods computes length of strings from 0 to 64. That is repeated 100000 times and time is reported in milliseconds. Every test is repeated 8 times using 8 different alignments of original strings.
Note, that higher bar means worse performance. Groups are for different variants, and inside each group we can see results for different alignments.
First run was on my home mac-mini machine (2.3 GHz Intel Core i7, Maverick):
We can see, that per-byte methods 2,3 are the worst, methods 1, 4, 5, 8 has almost identical performance. Which is a surprise, I thought that SSE2 will be better, it runs 128bit at once, not 64. Also, alignment of strings doesn't seems to matter, which is another surprise.
And the second is on my travel macbook (Processor 1.1 GHz Intel Core M, Sierra):
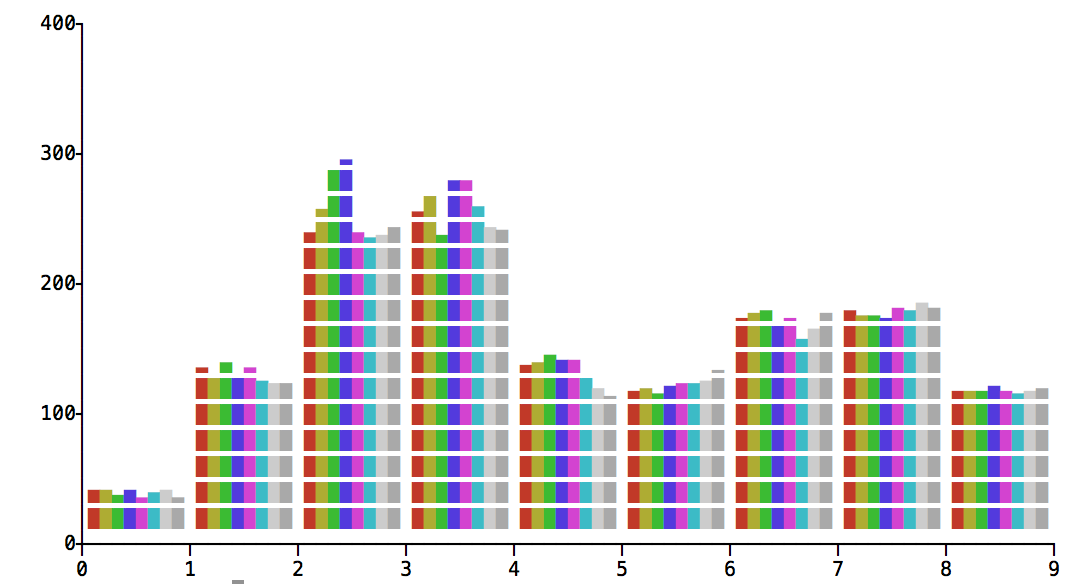
Below is a result of running test on Windows, with our project compiler and library, by two machines: a newer one (Intel Xeon CPU E5-1650 v3 @ 3.50GHz; Windows Server 2016, 64 bit) and an older one (Intel Core i7 CPU 920 @ 2.67Ghz; Windows Server 2008R2, 64 bit). Also I didn't run SSE2 test on them.
So, the built-in and per-byte tests are the worst. The older machine, the less that difference.
Also, I run the test with 32-bit compiler and the results are similar.
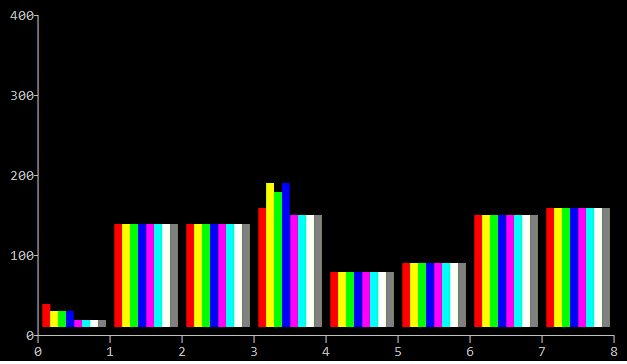
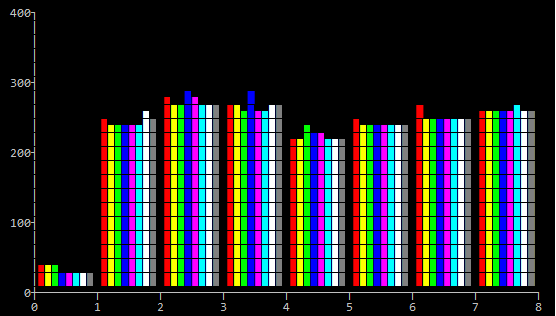
So, the morale is that per-byte is bad and 64-bit C++ is as good as SSE2.
Here is the code:
int _strlen1(const char *s){
return strlen(s);
}
int _strlen2(const char *s){
const char *s0=s; while(*s) s++; return s-s0;
}
int _strlen3(const char *s){
uint l=0; while(*s){ s++; l++; } return l;
}
int _strlen4(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
s=(const char *)p; while(*s) s++; return c+(s-(const char *)p);
}
c+=8; p++;
}
}
int _strlen5(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x) return x&0x00000000ffffffffull ?
(x&0x000000000000ffffull ?
(x&0x00000000000000ffull ? c : c+1) :
(x&0x0000000000ff0000ull ? c+2 : c+3)) :
(x&0x0000ffff00000000ull ?
(x&0x000000ff00000000ull ? c+4 : c+5) :
(x&0x00ff000000000000ull ? c+6 : c+7));
c+=8; p++;
}
}
int _strlen6(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
const uint64 y=(x|(x<<8)|(x<<16)|(x<<24)|(x<<32)|(x<<40)|(x<<48)|(x<<56))^m;
const uint64 z=y+(y>>8), u=z+(z>>16), l=u+(u>>32);
return c+((l>>7)&0xf);
}
c+=8; p++;
}
}
int _strlen7(const char *s){
const uint64 *p=(const uint64 *)s; uint c=0;
for(;;){
const uint64 m=0x8080808080808080ull;
const uint64 x=(((*p&~m)+~m)|*p)&m^m;
if(x){
const uint64 y=(x|(x<<8)|(x<<16)|(x<<24)|(x<<32)|(x<<40)|(x<<48)|(x<<56))^m;
const uint64 l=y+(y>>8)+(y>>16)+(y>>24)+(y>>32)+(y>>40)+(y>>48)+(y>>56);
return c+((l>>7)&0xf);
}
c+=8; p++;
}
}
int _strlen8(const char *s){
const __m128i z = _mm_setzero_si128();
const __m128i* p = (const __m128i*)s;
for(;;){
__m128i xmm = _mm_loadu_si128(p);
const uint mask = _mm_movemask_epi8(_mm_cmpeq_epi8(xmm,z));
if(mask!=0) return ((const char*)p)-s+(ffs(mask)-1);
p++;
}
}
2017-04-04
Zion National Park



Удобнее всего было взять самолет до Las Vegas, и поехать в Zion на машине. При этом за три часа пути проезжаешь из штата Nevada через Arizona в Utah.
Занятно, как рядом мирно сосуществуют штат Nevada, где официально разрешены казино и проституция, и Utah, где живут мормоны, которые даже кофе не пьют.
Las Vegas мне не нравится, поэтому вернемся в Zion. Парк, начинается в уютном городочке Springdale и его доступная территория помещается в одном небольшом каньоне, прорезанного речкой, текущей с верхнего плоского плато в нижнее. По нижней части парка ходит бесплатный автобус, в верхнюю надо ехать самому на машине через тоннель, или взбираться пешком по одной из троп.
Нижняя часть образована красным песчаником и состоит из вертикальных отвестных скал. Верхняя - из красного или белого песчаника и вся изрезана слоистыми горизонталями. Полная визуальная противоположность.


2017-03-28
Bryce Canyon


Bryce Canyon - волшебное место, рай для фотографа. Или ад, если пытаться снять что-то никем не снятое. На панораме глюкнула матрица на артефактах, но каньон получился хорошо. Удивительно, как природа иногда вдруг генерирует сложность из ничего, посреди однообразной равнины. Так, наверное, образовалась наша вселенная, в уголочке, из ничего, посреди бескрайней пустоты.
2017-03-01
Цвет моря



На закатной фотке, кстати тоже виден переход, но он уже не дает изменения цвета.
2017-02-28
Inuksuk

An inuksuk (plural inuksuit) (from the Inuktitut: ᐃᓄᒃᓱᒃ, plural ᐃᓄᒃᓱᐃᑦ; alternatively inukhuk in Inuinnaqtun, iñuksuk in Iñupiaq, inussuk in Greenlandic or inukshuk in English) is a human-made stone landmark or cairn used by the Inuit, Inupiat, Kalaallit, Yupik, and other peoples of the Arctic region of North America. ... The word inuksuk means "that which acts in the capacity of a human." (Wiki)
"in the capacity of a human" is exactly what I've written two years ago.
The photo has been shot this Sunday in Vancouver BC.
2017-01-12

2017-01-11
Какое небо голубое...
 Популярная шутка о том, что "нет никакого облака, есть чьи-то компьютеры", создает ощущение, что это компьютеры других пользователей, хотя облаком обычно называют програмно-аппаратную систему, работающую в дата-центрах.
Популярная шутка о том, что "нет никакого облака, есть чьи-то компьютеры", создает ощущение, что это компьютеры других пользователей, хотя облаком обычно называют програмно-аппаратную систему, работающую в дата-центрах.С технической точки зрения все выглядит правильно и хорошо, cloud storage, cloud computation - означают вполне конкретные и довольно передовые технологии. Однако будучи маркетинговым словом, cloud совершенно не всегда означает именно эти технологии, часто это просто способ продать пользователю воздух за дополнительные деньги.
Я просто перечислю, что получается, когда программа вдруг становится "облачной":
- Ваши файлы/фотографии вдруг начинают копироваться куда-то на сервера, возможно даже удаляясь при этом локально.
- По пользовательскому соглашению, ваши файлы могут уже не быть вашими, а вдруг становятся собственностью компании или могут быть переданы третьим лицам.
- Если они даже декларируются как только ваши, это может поменяться в любой момент.
- Неизвестные люди могут вдруг получить доступ к вашим файлам/письмам/фотографиям, причем даже к тем, которые вы удалили, либо работая в дата-центре, либо разбирая выкинутые дата-центром диски, либо просто подобрав пароль. Разнообразные органы тоже могут получить такой доступ.
- Фотографии вдруг могут быть сжаты новым алгоритмом, уменьшены в размерах и очищены от внутренних тегов.
- Вы не можете больше отказаться от установки новой версии программы, даже если она вам не нравится, без потери доступа к файлам.
- Без доступа к интернету некоторые файлы вдруг становятся недоступны.
- С доступом к интернету, они иногда становятся недоступны тем не менее.
- Становится сложно сделать бакап всех файлов или скопировать их все обычным файловым копированием.
- Быстрая когда-то программа вдруг становится медленной. Скорость программы может зависить от географического положения пользователя или качества соединения с интернетом.
- Компания может захотеть перевести всех на web-интерфейс. Приложения для десктопов и телефонов могут быть переделаны, чтобы тоже работать через тот-же интерфейс, завернутый в окно приложения. Обычно при этом функциональность и удобство резко падают. Приложения становятся тормозными и неудобными, но более дешевыми в разработке.
- Можно легко потерять доступ ко всем своим файлам, если вдруг компания откажет вам в сервисе. Это может быть вызвано, например сомнительными операциями по вашей кредитке, или подозрением на то, что в файлах содержится порнография. Компании всегда проще заблокировать ваш доступ и удалить все файлы, чем разбираться, подвергая себя риску.
- Компания может решить закрыть проект или разориться. Скачать при этом все файлы может оказаться проблематично.
- Забыв оплатить в течении некоторого времени (забыв обновить кредитку, например), можно потерять все файлы.
- Компании любят брать помесячную подписку вместо однократной продажи. При этом стоимость программы часто возрастает на порядок (например, $10 в месяц, вместо $80 однократной, при этом в качестве оправдания дается доступ к другим ненужным вам сервисам той же компании).
Из положительных сторон облачности обычно всего несколько:
- Вам обещают, хотя и без каких либо гарантий, что данные будут храниться более надежно.
- Они будут доступны с нескольких компьютеров, с телефонов и через Web-интерфейс.
- Иногда возможна sharing and collaboration.
Для себя я решил не опираться на облачные сервисы для файлов, которые считаю важными. Лучше делать собственные бакапы, включая обязательно off-site backup. Для доступа с разных компьютеров можно завести небольшой домашний сервер или держать шифрованную копию данных в public cloud.
Если все же пользоваться облачными сервисами, то только для файлов, которые и так публичные. Типа, например, этого блога. И все равно надо иметь свою резервную копию.
Subscribe to:
Posts (Atom)